
谷歌AI吃罚单背后,传统内容版权的博弈故事丨AI版权战事①



谷歌成为了全球第一个为AI训练交版权罚款的公司。
法国竞争管理局近日表示,谷歌侵犯了新闻机构版权,尤其是在未经允许的情况下,大量使用了法国出版商和新闻机构的内容训练大模型Gemini,而且没有告知媒体或监管方,对此处以2.5亿欧元的罚款。
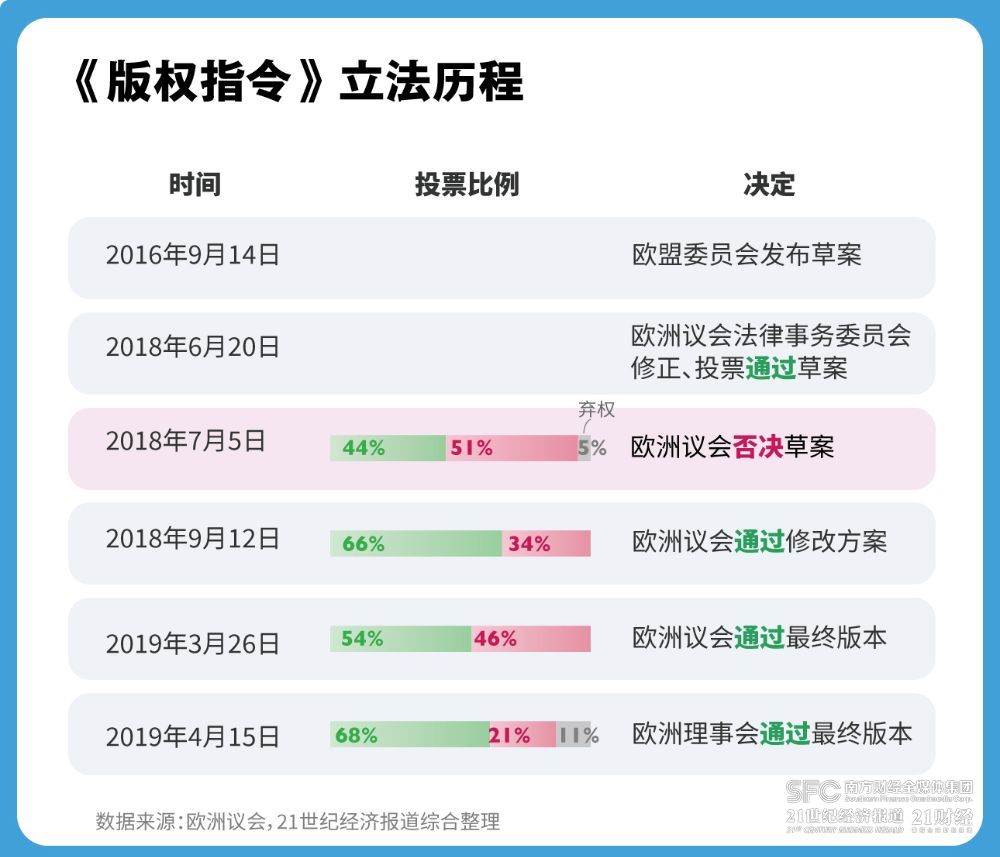
不过,这仍然是一个“新瓶装旧酒式”的处罚决定,处罚背景是2019年的欧盟《数字化单一市场版权指令》(以下简称《版权指令》)。
《版权指令》是互联网时代欧盟版权法的首次更新,要求互联网平台“尽最大努力”获得电影、音乐制作人等版权方的许可,并迫使谷歌跟新闻界达成一系列版权承诺。这一过程结束了互联网长期以来的免费午餐,可以说是欧盟政策史上最暴烈、最白热化的一场斗争。
从立法过程到立法结果,《版权指令》值得被复盘,不仅仅因为它的内容直接影响了AI版权的走向——欧盟《人工智能法案》基本沿用了《版权指令》的表述。
更重要的是,在新技术的十字路口,新旧产业交锋仍在继续:一边是希望基于传统模式、获得高度版权保护的内容行业,一边是提倡免费、共享、技术创新的科技行业。去年12月《纽约时报》正式起诉OpenAI的训练数据侵犯版权后,新闻媒体The Intercept、Raw Story和AlterNet也加入了《纽约时报》阵营;今年3月,又有三位小说家起诉英伟达大模型侵权……
知识产权与经济秩序紧密相关,AI版权迷雾重重,过去两方如何博弈、如何抵达共识,都可能成为未来的指引。
诞生
对于《版权指令》的诞生,“单一数字市场战略”、“冈瑟·厄廷格(Guenther Oettinger)”是两个不得不提的关键词。
2015年,时任欧盟委员会主席提出了“单一数字市场战略”,旨在创造一体化的欧洲数字环境,版权改革正是一揽子计划中的一项。
当时版权由数字经济和社会部门负责,其中一名专员是冈瑟·厄廷格。厄廷格是一位50年代出生的德国人,Politico报道写道,在布鲁塞尔自命不凡的官场世界中,厄廷格给人的印象是口无遮拦、说话轻佻,但有着高超的谈判技巧。他被欧盟主席提名成为数字专员,“对欧洲数字化政策的影响力可以说比任何官员都大。”
但厄廷格本人的生活其实不太“数字化”。比如,在2016年德国汉堡的一场公开演讲中,厄廷格在台上坦然说,他的家里没有装WiFi,更喜欢读报纸而不是刷 Twitter,更喜欢把文档打印出来而不是看平板。他的个人特点也影响了《版权指令》的底色。
在任期三年里,厄廷格一直积极倡导媒体机构的“邻接权”——可以理解为一项较弱的著作权,最早在德国立法,主要由德国媒体巨头、欧洲最大报业集团Axel Springer推动。
华东政法大学知识产权学院副研究员阮开欣在文章中解释,邻接权扩大了新闻媒体的数字版权,如果想在“谷歌新闻”板块聚合新闻链接、标题、摘要,谷歌就得向媒体支付许可费。在此之前,虽然媒体机构对新闻的摘选编辑投入了大量精力,但这些成果往往达不到著作权意义上的作品标准,也无法从网络二次传播中获利。
2016年欧盟委员会的《版权指令》草案公布后,一石激起千层浪。争议的焦点,除了草案第11条的媒体邻接权,还有草案第13条规定互联网平台有“授权寻求义务”和“注意义务”:平台必须尽最大努力获得版权方的许可,并阻止传播用户上传的侵权内容。这一注意义务意味着,平台得开发自己的版权识别技术,过滤用户上传的内容。
因为这两点争议,《版权指令》踏上了一条波折的立法之路。
(图:21经济报道记者综合整理)
暗战
版权法的核心作用是保护版权方获得公平合理的报酬,激励持续创作。几乎每一次版权规则迭代都与新的传播技术、新的商业模式息息相关。
进入互联网时代,像谷歌、Facebook这样的内容聚合平台凭借强大的信息抓取能力,包罗了大量免费新闻报道、音乐、影视,收入也随之暴涨。另一边传统内容行业的生存空间却在一步步萎缩。
以媒体机构为例。媒体越来越依赖“流量+在线广告”的新模式营收,但数字化转型吃力,有两组数据可以解释这一点:一组数据是,欧盟委员会调查发现,通过搜索引擎、社交媒体看新闻的欧洲人中,47%的人不会点击原链接,仅仅只是看一眼社交平台上的摘要,这直接分走了媒体网站的流量。另一组数据则是,2006年,欧洲新闻出版行业获得了457 亿欧元的收入,到了2016年,整个行业营收骤降到296亿欧元,十年缩水了近40%。
在媒体机构看来,互联网平台只是内容的搬运工,却收割了大部分利益;媒体提供了最高质量的内容养料,却无法从中获得报酬。
但在互联网巨头看来,提供曝光渠道的他们已经仁至义尽。谷歌在一份公开声明中指出,“仅在欧洲,谷歌每个月就为新闻网站就贡献了超过80亿次点击量。”谷歌还表示,真正分走媒体流量的是其他网络娱乐内容,而不是平台本身。
哪一种说法更有说服力?关键在于谁能把自方利益最深地触达政策制定者,这离不开长期的游说工作。
政治媒体Politico分析,《版权指令》的最大政治推动者来自德国和法国。上文提到的冈瑟·厄廷格,一直被认为是媒体Axel Springer的“密友”,两者通过德国报纸出版商协会保持密切联系。传统媒体在这些国家历史悠久、根基深厚,行业组织有着很大的影响力。
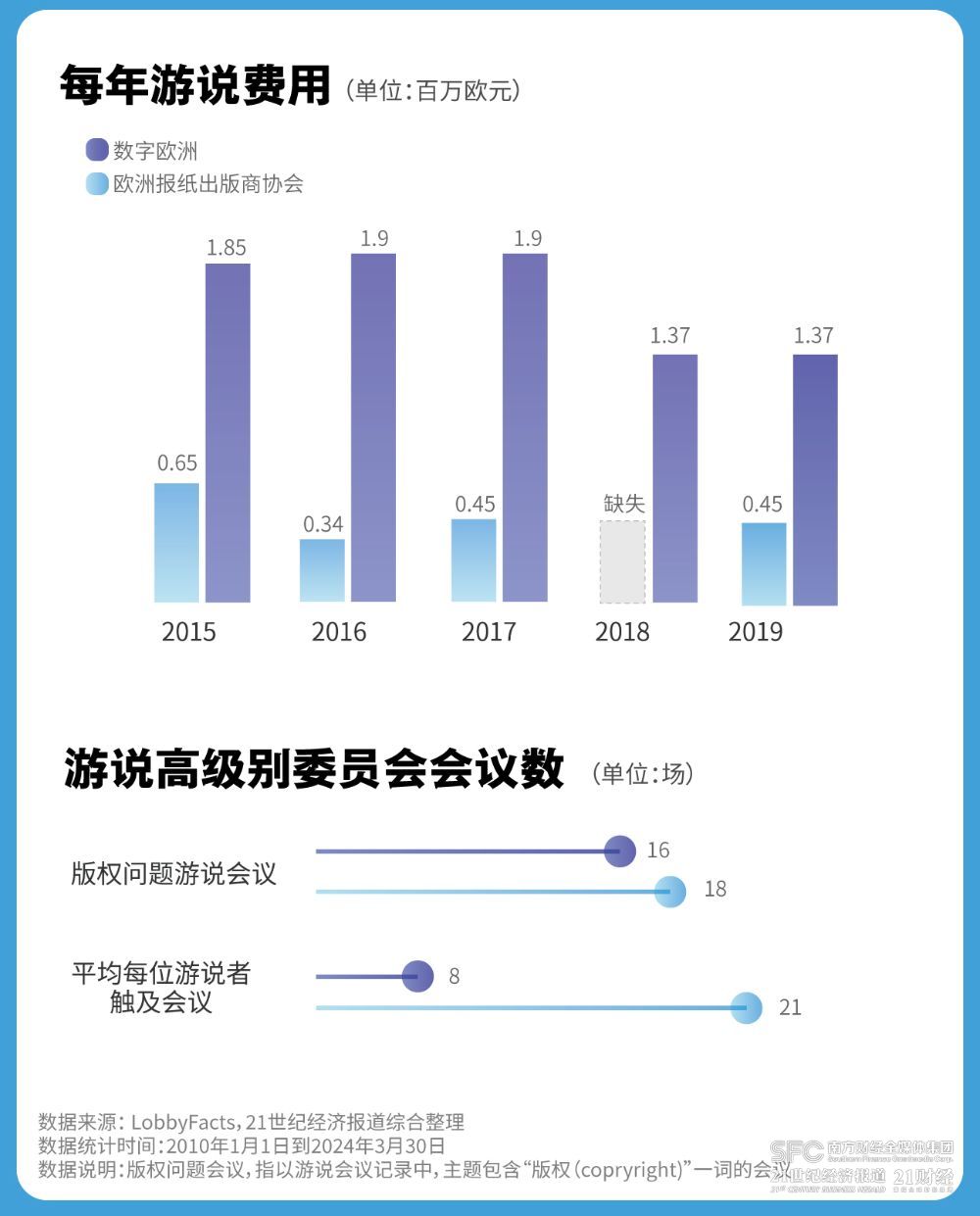
除此之外,代表媒体的三大行业团体——欧洲出版商委员会(EPC)、欧洲新闻媒体协会(News Media Europe)、欧洲报纸出版商协会(ENPA) 在版权问题上的存在感也很强,平均每年的游说费用超过三十万欧元。虽然跟科技团体相比,这一开销可以说是微乎其微,但它们的游说效率非常高。拿欧洲报纸出版商协会(ENPA)来说,认证的游说者只有3名,但平均每个人参与了21场高级别委员会的游说会议。
代表谷歌、微软、苹果等科技公司的游说团体数字欧洲 (Digital Europe) ,每年的游说开销都在百万级别,认证的游说者超过20名,不过平均每位游说者只能接触8场高级别委员会议。
缺少欧洲基因的科技团体,虽然豪掷千金,但往往是雷声大雨点小,能跟欧洲议员建立的联系其实要少得多。
(图:21经济报道记者综合整理)
不难猜到这场暗战的初步战果。2018年6月20日,欧洲议会法律事务委员会投票通过了《版权指令》草案,此前就饱具争议的第11条“新闻链接税”、第13条“版权过滤责任”几乎没有实质变动。
交锋
草案通过后,《版权指令》正式进入舆论视野,但欧盟解决矛盾的具体方案并不能让所有人满意。
至少有3类人发出反对声音:其一是学术界。有超过200名法律学者签署了一份公开反对信,他们担忧《版权指令》达不到预期的法律效果,在高度集中的市场面前,中小新闻媒体和中小互联网平台没有话语权,最终只会因为成本过高而倒闭;第二类反对者是互联网科技先驱。包括维基百科的创始人吉米·威尔士 、万维网发明者蒂姆·伯纳斯·李在内的70多位科技明星,公开发信谴责“版权过滤责任”的规定,指责它限制用户自由分享创作,“让开放、创新的互联网从此变为内容审查的工具。”最后,是更多类似谷歌的互联网聚合平台。
2018年7月开始,为了抗议《版权指令》,英语、意大利语、西班牙语、波兰语等维基百科要么直接关站,要么在网页上方打出硕大横幅——“维基百科有关闭的风险。”“如果草案被通过,新闻可能无法分享到社交网络上,连搜索引擎也可能再也搜不到它们了。” 发动用户在投票前去联系熟悉的欧洲议会议员。
后来一位欧洲议会的媒体发言人回忆,“议员们从没收到过这么多电话、邮件的轰炸。”
作为法案的核心起草者,德国议员阿克塞尔·沃斯 (Axel Voss) 对此感到很无奈。在第一次正式投票之前,沃斯在欧洲议会上发表了一番慷慨激昂的演讲:“我们谈论的是谷歌和 Facebook 等美国主要平台,它们以牺牲欧洲创作者为代价赚取巨额利润。”他告诉议员们,“我们应该站在欧洲创作者一边,否则创作者有破产的风险。”
7月5日,第一次投票,欧洲议会以40票的差距否决了《版权指令》,法案需要重新审议。
沃斯在采访中把这次投票失败归咎于科技巨头的煽动,让公众(尤其是“议员们的小孩”“年轻人”)误解了条款。在之后的两个月里,他努力在各种公开场合解释《版权指令》并不影响公众利益,比如,维基百科这样的非商业性使用不受影响。再比如,二次创作的表情包和玩梗(meme)属于讽刺、戏仿性质的自由上传,同样不受《版权指令》约束。
为了增加《版权指令》的通过机会,沃斯采取了“绥靖政策”,直接限缩草案的适用范围,明文排除上述行为。在第二次投票的前几天,沃斯还很忐忑,他不确定这项努力是否有效,“但这是最有可能成功的办法了。”
9月12日,投票结果宣布时,沃斯显然松了一口气。修改方案以212票的优势通过欧洲议会。
成果
在阮开欣看来,《版权指令》已经通过豁免排除了舆论最担忧的两个问题,后来的反对意见大多存在误解,不足以否定欧盟的立法动因,因此最终没被采纳。
对于阻碍信息流通的争议,《版权指令》的最终版本明确规定了非商业使用、分享超链接、摘要新闻个别单词,不需要向媒体“交版税”。
而限制中小企业发展的问题确实存在,因为只有规模足够大、资源足够充足的平台,才有可能开发版权识别技术、过滤用户上传的内容,以此满足高标准的注意义务。对此《版权指令》直接豁免了中小企业,规定在线运营不足3年且年营业额少于1000万欧元的创业型平台,采取“通知-删除”的行动即可。
可以说版权规则的例外和豁免,起着平衡多方利益的重要作用。甚至有支持阵营的议员后来表示,《版权指令》最终例外过多,作用被“大大淡化了”,“不太可能产生重大影响。”
广东财经大学法学院教授姚志伟认为,《版权指令》最主要的影响是通过稳定的制度安排,提供确定性和可预测性,为整个内容产业许下明确的承诺。
谷歌就是一个现实案例。《版权指令》在2019年落地生效后,法国迅速将其转化为了国内法。谷歌一开始直接关闭了法国的新闻板块以避免付费,但监管机构很快介入,认为谷歌在滥用市场支配地位,随后又认定谷歌在和新闻出版商的谈判中存在重大违规行为。
谷歌为此付出了漫长的谈判成本,以及5亿欧元的罚款。2022年,谷歌与法国280家新闻出版商签订了版权承诺,每年支付千万欧元级别的版权费,新闻内容领域的业务从此置于严格的监管视线之下。
不过阮开欣也指出,这是欧盟在内容出版行业的利益确实被侵蚀的情况下,才做出的决定。知识产权与经济秩序紧密相关,产业发展状态很重要。
姚志伟同样提醒,全球几乎只有欧盟作出了类似的规定。内容出版行业在欧洲历史悠久,在互联网发展时期,几乎没有互联网巨头诞生在欧洲,《版权指令》当时要考虑的利益抉择其实比较少。
新博弈,新叙事
有意思的是,曾经为内容产业呼吁改革的主力军德国、法国,现在都有了自己的明星AI大模型。欧洲媒体集团的核心Axel Springer也成了最早一批和OpenAI签署协议的版权方。
除此之外,《版权指令》在2019年就颇有前瞻性地规定了“文本与数据挖掘行为属于例外”。文本与数据挖掘技术是机器学习和人工智能开发的核心之一,欧盟似乎早已瞄准了未来的发力点。
同济大学法学院助理教授、上海市人工智能社会治理协同创新中心研究员朱悦告诉21世纪经济报道记者,《版权指令》和近期通过欧洲议会的《人工智能法案》的联系非常紧密,实际上它们一直在同时进行讨论。目前关于AI的版权规定主要放在了《人工智能法案》中,它基本沿用了《版权指令》的表述,包括豁免文本与数据挖掘、尊重版权方作出保留的权利。
但无法回答的问题还很多。
比如在这一次的AI版权罚款事件中,谷歌主张在训练AI的过程中抓取新闻报道,理应属于《版权指令》允许的文本与数据挖掘行为。但法国竞争管理局回复,训练AI能否被豁免“还不清楚”。
姚志伟指出,直接原因是《版权指令》的豁免前提是非商业性使用,训练Gemini这样的商业使用行为难以援引条款。进一步从技术本身来看,文本与数据挖掘针对的是算法推荐,也不是生成式AI。朱悦解释,“传统版权法保护的是复制、放映、传播等行为,文本与数据挖掘是一类相对新兴的行为,而生成式AI就更新兴了——如果我们细看大模型训练过程的每一步,它可能没办法归类于现在版权法中的任何一种行为。”
本次法国的处罚主要是基于谷歌“没有透明告知AI使用了版权方内容”。朱悦也表示对内容版权方的利益保护,最终可能需要靠收放透明度的要求来完成。
透明度能为各方提供充分信息,版权方就能有更多证据去争取有利的补偿。《版权指令》要求互联网平台在谈价前提供充分信息,《人工智能法案》也设置了透明度要求。
在这一方面,新闻媒体有着特殊性,因为互联网巨头与新闻界有过单独约定,也已经建立起版权补偿的惯例。谷歌曾在2022年跟法国新闻机构承诺,在接到版权投诉的三个月内,要基于透明原则重新谈判。所以法国出版商很快就能收到谷歌的一份叙述性摘要,详细说明Gemini到底是如何训练使用他们的新闻报道的。
但总体来看,披露AI系统远远比披露互联网搜索引擎复杂。朱悦指出,《人工智能法案》为透明度如何操作做了一些留白,包括要披露哪些信息、如何披露、涉及商业秘密应该如何处理。接下来可能会通过监管指南、个案裁判和各国国内的监管来逐步细化规则。此外,欧盟内部的利益相关方也没有放弃推动重修《版权指令》。
AI时代新一轮的博弈,将在这些环节重新展开。




