
GPT明年有望开源?大模型开源与安全的博弈



就在圣诞前夕,OpenAI CEO 山姆·奥特曼在社交平台上送出了一份“圣诞礼物”:2024年的OpenAI愿望清单。
这份清单来自奥特曼在12月24日向网友征集的回答“你希望Open AI明年能完成哪些事情?”奥特曼除了否认AGI通用人工智能的请求(在旁边备注着:还需要更多耐心),对其他请求并没有作出额外评价。

在这12项发展目标中,开源也许是最引人关注的一项。虽然OpenAI一直在推进开源项目——语音识别模型Whisper、文生3D模型Shap-e、解码器Consistency Decoder,但它们都不是ChatGPT。而此次回应似乎暗示着,公众翘首以盼的GPT开源模型正在提上日程。
作为自称“开放AI”的OpenAI,自GPT-3不再公开源代码以来,一直面临开源压力。这种压力一面来自竞争对手Meta、法国黑马公司Mistral AI为开源大模型的造浪,另一面则来自监管侧对开源大模型的宽容态度。而ChatGPT坚持闭源的一个官方理由是:为了安全。
开源不仅仅是OpenAI头顶盘旋的幽灵,也是业内众说纷纭的一道安全选择题。大模型开源意味着什么?开源、闭源大模型能否在安全性上一分高下?
OpenAI的开源压力
尽管大模型前期发展由闭源大模型主导,但开源军团来势汹汹。
如果回看大模型的开源浪潮,能发现两个明显的分水岭:一个是2022年11月,闭源大模型产品ChatGPT向公众开放。根据同济大学法学院助理教授、上海市人工智能社会治理协同创新中心研究员朱悦的观察,在ChatGPT流行之前,更多时候开源是默认,不开源才是例外。随着GPT的发展,整个 AI 领域变得更加商业化,情况有了明显变化。
另一个则是今年7月,Meta的开源大模型Llama 2公开商用,开源大模型重新引领风向。有诸多应用厂商和初创公司随后站上了这一风口。21世纪经济报道记者检索到,截至今年12月底,开源社区Hugging Face上公开的模型数量已经超过了40万个,与半年前的20万个预训练模型相比,数量增长了近一倍。
开源,字面上指的是公开源代码。从监管目前使用的定义来看,朱悦表示大模型开源还指向权重等核心参数和使用信息,属于模型架构的核心。如果开源,通常意味着模型是公开透明、即插即用的。
不过,北京邮电大学人工智能学院副教授陈光告诉21记者,“我们现在更倾向于叫开放模型,而不是开源模型。”
陈光长期研究模式识别和机器学习,在他看来,大模型的“开源”往往是有限的公开——普遍公开的是模型架构、训练方法,但很少公开训练数据和过程。以开源界的明星Llama 2为例,具体用了哪些训练数据,如何组织、控制训练过程,两个关键信息并未公开。再加上算力限制,大模型即使公开了源代码,要完全重构、复现目标模型也几乎不可能,只能在参数范围内小幅调整。
“可以把大模型想象成一个调音盒,盒子上有很多旋钮,通过调试不同的旋钮发出千差万别的声音,公开的参数就是最终的声音状态。但重要的是旋钮要怎么调?需要调到什么状态?这些取决于没有公开的训练数据,还有训练过程中大量经验性的工程技巧。”陈光进一步解释。
正因如此,大模型开源与传统的开源软件并不一样,开源界对此的争议声不小。开放源代码促进会(Open Source Initiative)就指出,对于传统的开源软件,一个核心定义是源代码公开、可用、可复现任何目的。但对于大模型,如果要复现能力,还需要公开训练数据、推理代码等一系列可能牵扯隐私和版权问题的信息。“开源 AI 的概念目前没有定义,不同的组织用它表示不同公开程度的东西,这会让人们对开源感到困惑。”该组织的执行董事此前表示。
一个更重要的问题也许是,这种“有限的开放”为什么有如此大的吸引力?
陈光提到,开源模型通常会发布不同的参数版本,内部可能会训练一个大规模模型,但公开的一般是中等或小规模的模型。记者梳理发现,开源模型的参数控制在6B-70B之间。陈光解释,除了商业竞争因素,考虑到算力、计算资源等成本问题,大部分研究机构、初创企业、应用厂商“跑不动”更大参数的模型,因此参数小的开源模型一般更受欢迎。
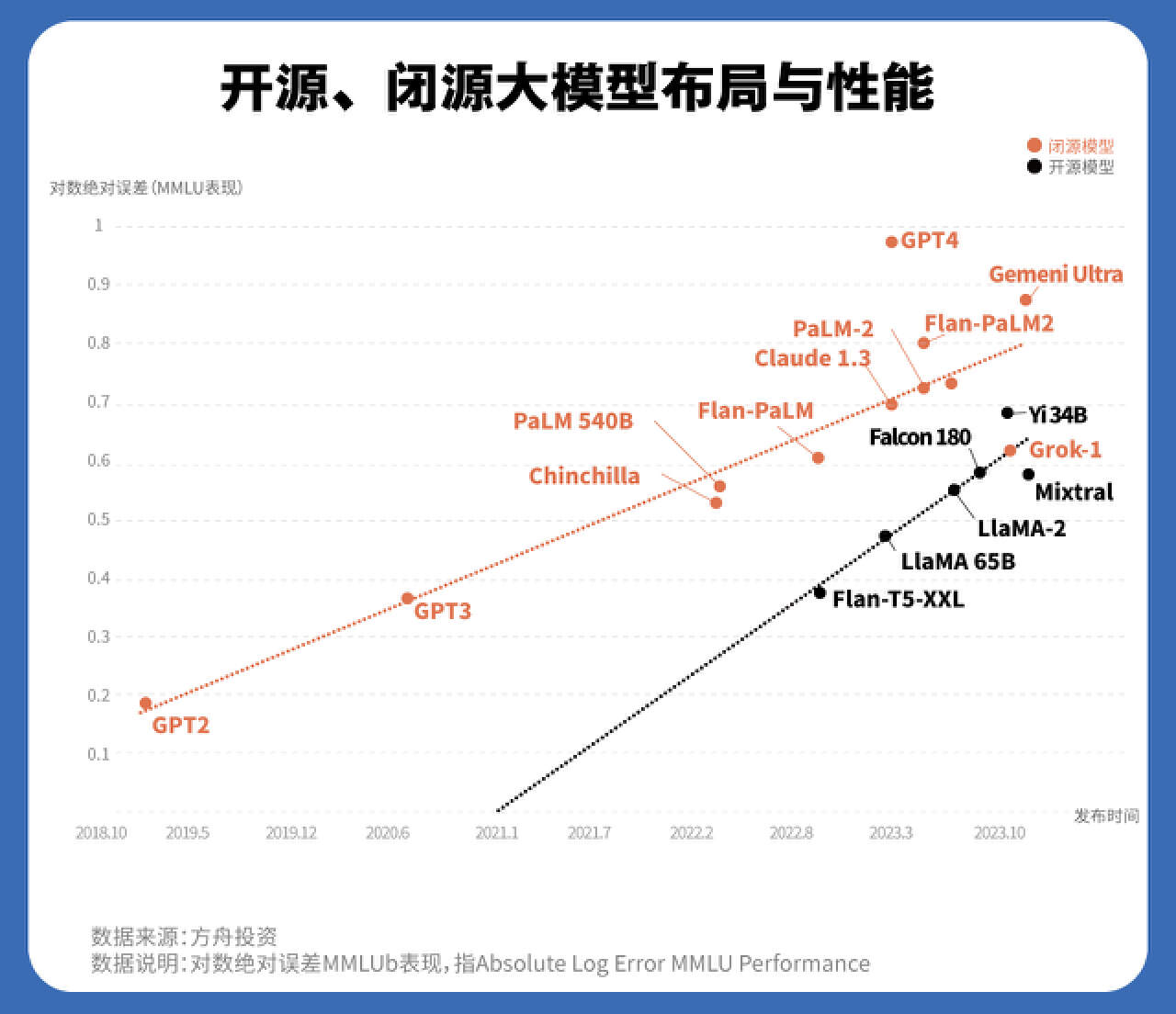
而更关键的是,开源模型的性能在不断提升。众所周知,开源这一“众包”方式,能不断改进、提升研发效能,长期则能盘活研发社区,促进整个生态发展。这一经验在大模型上也已经有了初步佐证:在上文方舟投资为开源模型与闭源模型绘制的散点图中,两者性能的差距越来越小。Meta 首席 AI 科学家对此感叹:“开源人工智能模型正走在超越专有模型的路上。”换句话说,用更少的成本达到跟专有模型相差不远的性能,将是开源模型越来越显著的优势。
除此之外,监管也往往对开源模型持有更宽容的态度。比如,正在谈判中的欧盟《人工智能法案》就增设了开源例外。“对于AI生态来说,开源是一个通行做法,也是大家比较认可的理想规范。无论是欧洲还是美国,通常把开源大模型视为一种规制程度较轻的研发活动。”朱悦说。
知道了这些,就不难理解OpenAI面临的外界压力,以及“开源模型步步紧逼专有模型”的说法了。
业内的安全争议
如果再深入一步开源、闭源大模型的战火,可以发现两方都执矛“安全性”。
开源方的主要观点是,计算机技术领域早已验证开源更安全。开源运动的“座右铭”林纳斯定律(Linus's Law)可以很好地解释安全性,该定律表示:“有足够多的眼睛,就可让所有问题浮现。” 鲜明举起这一旗帜的有法国黑马公司Mistral AI——Mistral 坚信,生成式 AI 技术应该是开源的,广泛分享大模型的源代码是最安全的途径,因为有更多的人可以审查这项技术、发现缺陷,并通过社区修复或减轻威胁。持同样观点的还有a16z风投公司的合伙人,该合伙人在采访中表示:“没有一个工程团队能找出每一个错误。开源社区擅长构建更便宜、更快、更安全的软件。”
闭源方的观点也逻辑扎实。OpenAI 和谷歌都曾警告,在开源领域发布能力如此强大的大模型是非常危险的,因为技术可能落入恶意人士之手。兰德智库最新的一份研究报告《保护人工智能模型权重》列出了40种不同的攻击向量,该报告强调,一旦获得模型权重,恶意行为者可以用很少的代价利用完整的模型。
在安全性的天秤上,谁的份量更重?
一位网络安全领域的资深人士向21记者指出,大模型开源与软件开源并不一样,其安全风险的范围也更为复杂。
陈光认为,安全风险主要体现在五个维度:审查和修复机制、透明度、责任分配、恶意使用、恶意攻击。在修复机制和透明度上,开源模型能吸纳更多社区成员参与修复,模型构造也相对透明、可信,其优势不必赘述。而对于传统网络安全领域的恶意攻击,“可以类比开源的linux操作系统和闭源的windows操作系统,linux系统有很多用户给它挑bug,可以不断改进。从这个角度来看,开源模型能更及时地发现和修补漏洞。”
而开源模型最大的弊端恐怕在于,容易被恶意使用,以及责任分配不明。相比有后台监测人员的闭源模型,开源模型的一个特性体现在,只要不主动报告漏洞,通常可以一直利用。此外,还可以在公开代码的基础上修改出不设限的版本,比如创建黑客工具、网络钓鱼页面和无法检测的恶意软件。
目前在暗网流行的DarkGPT、DarkBERT 和 DarkBARD就是恶意使用的典型例子。据外媒报道,它们是“专为欺诈者、黑客、垃圾邮件发送者和志同道合的个体设计的新型专有模型”。这些非法改编大模型一年收取500到700美元的订阅费用,正逐渐发展为一种商业模式。这样来看,对开源大模型的滥用担忧并非杞人忧天。
开源模型的责任分配也是一个问题。陈光解释,“开源通常意味着责任更分散,而闭源责任集中于提供者,可能促使公司更积极地维护产品的安全性。”
在陈光看来,开源、闭源模型各有利弊,需要根据实际的场景做出判断:“使用场景是什么,可能有哪些风险,开源和闭源哪一类更利于规避风险?从自身的资源看,有没有能力组建足够强的安全团队?如果开发团队只有10个人,即使监测到了漏洞,内部想及时修复也很难,这种情况还不如开源。”
朱悦补充道,以欧盟的《人工智能法案》为例,在针对开源大模型制定监管政策时,仍然根据风险做了分级设计。比如通用目的或者高风险的人工智能即使开源,也不是完全豁免。此外,如果自身开源社区发展有限,那么开源还涉及对国外社区的依赖度,以及自主创新问题。可以说商业能力、整体开源文化和实际发展生态,都是开源技术背后更复杂的影响因子。
由此来看,即使只用安全性这一个标准衡量,开源、闭源模型也没有高下之分。两者不必然通向安全,都需要付出大量努力。
而回到大模型的明星厂商身上,比起用技术制造更多的营销噱头,付出实际行动似乎更加必要。就像网友在评论区对山姆·奥特曼回复的那样——让产品按承诺运行就好。(just make the product work aspromised)




